Other than ILP, the only scalable and general-purpose way we know how to increase performance is through multiprocessing. Multiprocessing arose from the demand for computation over massive amounts of data. In server environments there is significant natural parallelism, arising from large datasets.
Multiprocessors
Multiprocessors are computers consisting of tightly coupled processors whose coordination and usage are typically controlled by a single operating system and that share memory through a shared address space. Such systems exploit thread-level parallelism through two different software models.
Parallel Processing
The execution of a tightly coupled set of threads collaborating on a single task.
Request-level parallelism
The execution of multiple, relatively independent processes that may originate from one or more users. This may be exploited by a single application running on multiple processors, such as a database responding to queries, or multiple applications running independently, often called multiprogramming.
Single-chip systems (processor) with multiple cores is known as a multicore processor.
Communication Models
A Communication model defines how the different cores communicate with each other
Shared Address Space
Cores communicate using normal load/store instructions. Explicit synchronization is required because the receiving core needs to know when the store has completed.
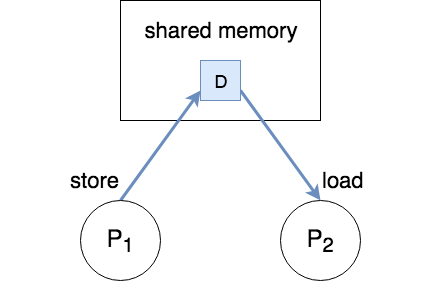
In order to communicate data from P1 to P2, P1 first has to store the data to shared memory and thereafter P2 can load the data from memory.
Message Passing
Cores communicate by explicitly sending and receiving messages between them. Synchronization is implicit because when the receive has happened we also know that the send has happened.
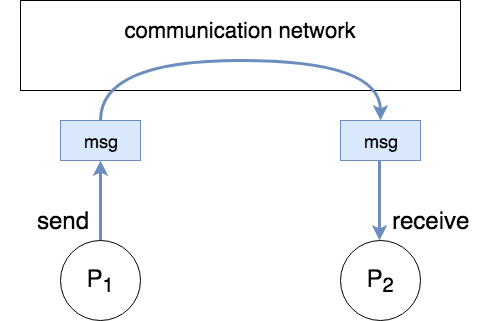
To communicate data from P1 to P2, P1 has to send the message through the communication network and P2 has to explicitly receive it.
Classes of Shared-Memory Multiprocessors
Communication among threads occurs through a shared address space, meaning that a memory reference can be made by any processor to any memory location, assuming it has the correct access rights.
Symmetric(Centralized) Multiprocessors (SMPs)
Processors share a single centralized memory that all processors have equal access to, hence the term symmetric. They are called uniform memory access (UMA) multiprocessors, arising from the fact that all processors have a uniform latency from memory, even if the memory is organized into multiple banks. Features small numbers of cores, as the memory system would not be able to support the bandwidth demands of a larger number of processors without incurring excessively long access latency.

Multiple processor–cache subsystems share the same physical memory, typically with one level of shared cache, and one or more levels of private per-core cache. The key architectural property is the uniform access time to all of the memory from all of the processors.
Distributed Shared Memory (DSM)
To support larger processor counts, memory must be distributed among the processors rather than centralized. Distributing the memory among the nodes both increases the bandwidth and reduces the latency to local memory.
A DSM multiprocessor is also called a NUMA (nonuniform memory access), since the access time depends on the location of a data word in memory. The key disadvantages for a DSM are that communicating data among processors becomes somewhat more complex, and a DSM requires more effort in the software to take advantage of the increased memory bandwidth afforded by distributed memories.
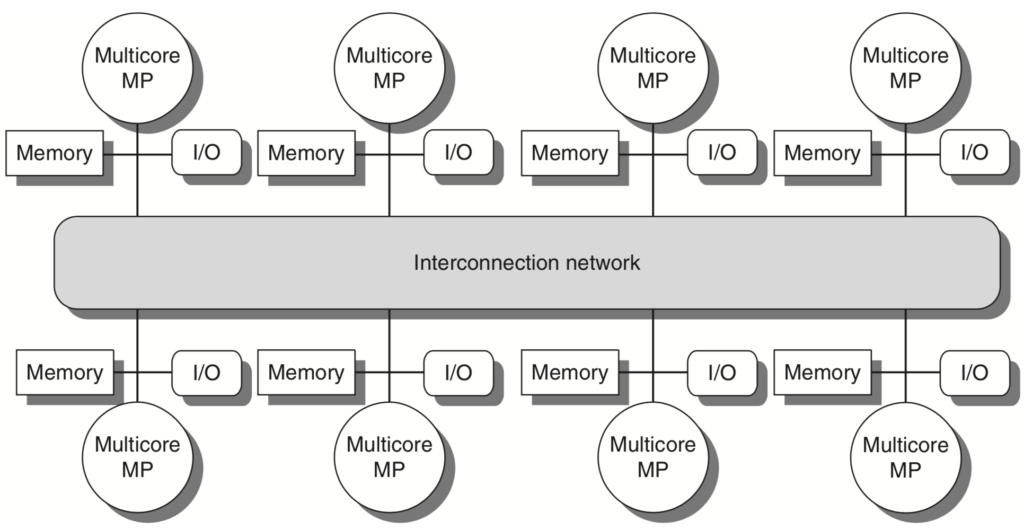
Each processor core shares the entire memory, although the access time to the lock memory attached to the core’s chip will be much faster than the access time to remote memories.