CUDA is a parallel computing platform and programming model that higher level languages can use to exploit parallelism. In CUDA, the kernel is executed with the aid of threads. The thread is an abstract entity that represents the execution of the kernel. A kernel is a small program or a function. Multi threaded applications use many such threads that are running at the same time, to organize parallel computation. Every thread has an index, which is used for calculating memory address locations and also for taking control decisions.
CUDA operates on a heterogeneous programming model which is used to run host device application programs. In this model, we start executing an application on the host device which is usually a CPU core. The device is a throughput oriented device, i.e., a GPU core which performs parallel computations. Kernel functions are used to do these parallel executions. Once these kernel functions are executed the control is passed back to the host device that resumes serial execution.
The CUDA parallel programming model has three key abstractions at its core
- a hierarchy of thread groups (computation)
- a hierarchy of memory spaces
- barrier synchronization
There are exposed to the programmer as a minimal set of language extensions.
CUDA Data Flow
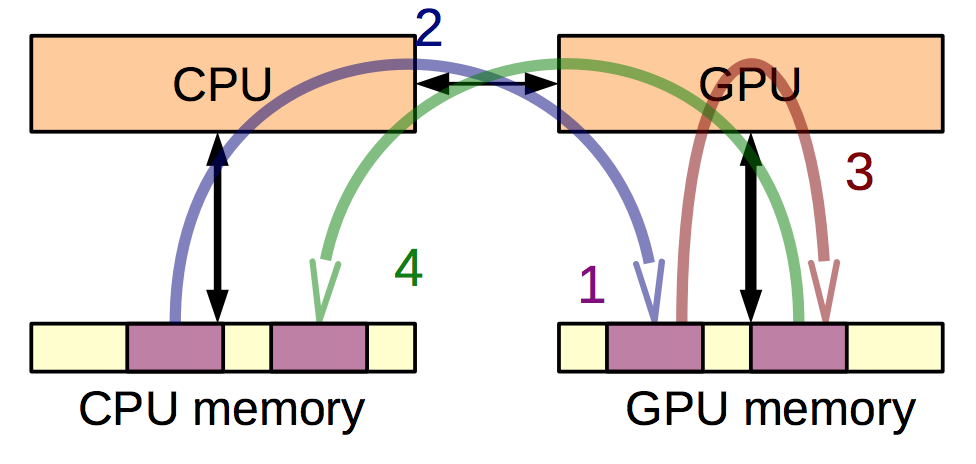
- Allocate GPU memory.
- Copy inputs from CPU memory to GPU memory.
- Run computation on GPU.
- Copy back results to CPU memory.