Threads
Single execution units that run kernels on the GPU. Similar to CPU threads but there’s usually many more of them.

Threads are shown as arrows. The wiggly lines indicate conditionals and branches.
Block
A thread block is a programming abstraction that represents a group of threads that can be executed serially or in parallel. For better process and data mapping, threads are grouped into thread blocks. The number of threads varies with available shared memory. The number of threads in a thread block is also limited by the architecture. The threads in the same thread block run on the same streaming processor. Threads in the same block can communicate with each other via shared memory, barrier synchronization or other synchronization primitives such as atomic operations.
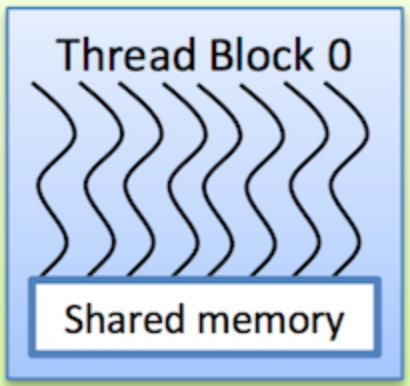
Thread blocks are drawn as boxes with threads in them.
Grid
Multiple blocks are combined to form a grid. All the blocks in the same grid contain the same number of threads. Since the number of threads in a block is limited, grids can be used for computations that require a large number of thread blocks to operate in parallel. A kernel is launched as a grid. Different kernels can have different grid/block configuration

Grid is a collection of thread blocks, each of which is a collection of threads.
Why Blocks and Threads?
Each GPU has a limit on the number of threads per block but (almost) no limit on the number of blocks. Each GPU can run some number of blocks concurrently, executing some number of threads simultaneously.
By adding the extra level of abstraction, higher performance GPU’s can simply run more blocks concurrently and chew through the workload quicker with absolutely no change to the code!
Synchronization
The threads of a block execute concurrently and may synchronize at a synchronization barrier by calling the __syncthreads() intrinsic. This guarantees that no thread in the block can proceed until all threads in the block have reached the barrier. After passing the barrier, these threads are also guaranteed to see all writes to memory performed by threads in the block before the barrier. Thus, threads in a block may communicate with each other by writing and reading per-block shared memory at a synchronization barrier.
Threads in different blocks cannot synchronize as the CUDA runtime system can execute blocks in any order.
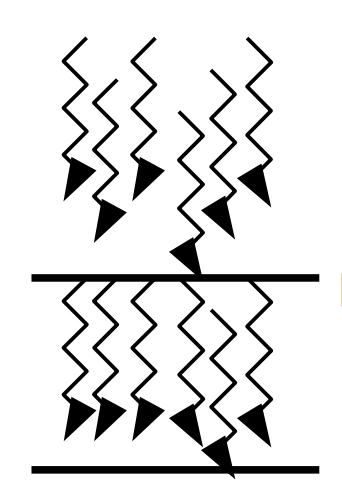
A barrier ensures that no thread in the block can proceed until all threads in the block have reached the barrier.