Hardware Perspective
Threads, thread blocks and grid are essentially a programmer’s perspective. From a hardware perspective, hardware groups threads that execute the same instruction in to warps. Several warps constitute a thread block. Several thread blocks are assigned to a Streaming Multiprocessor (SM). Several SM constitute the whole GPU unit (which executes the whole Kernel Grid).

Streaming Multiprocessors
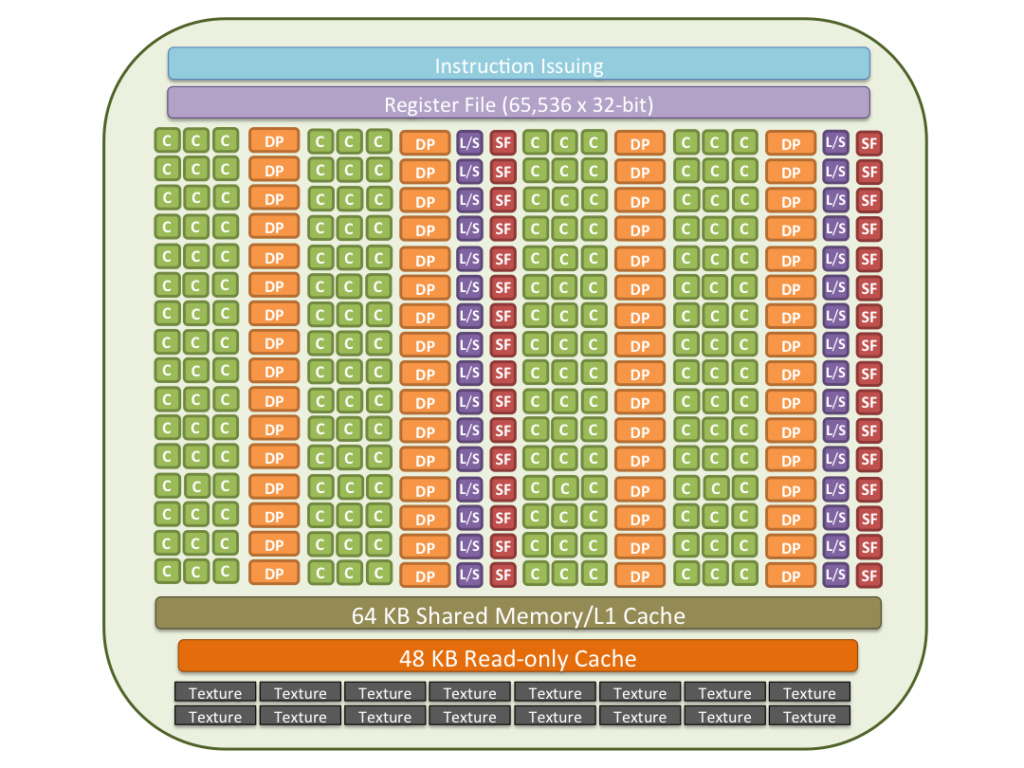
Each architecture in GPU consists of several SM or Streaming Multiprocessors. These are general purpose processors with a low clock rate target and a small cache. The primary task of an SM is that it must execute several thread blocks in parallel. As soon as one of its thread block has completed execution, it takes up the serially next thread block. In general, SMs support instruction-level parallelism but not branch prediction.
To achieve this purpose, an SM contains the following
- Execution cores. (single precision floating-point units, double precision floating-point units, special function units (SFUs)).
- Caches
- L1 cache. (for reducing memory access latency).
- Shared memory (for shared data between threads).
- Constant cache (for broadcasting of reads from a read-only memory).
- Texture cache. (for aggregating bandwidth from texture memory).
- Schedulers for warps. (these are for issuing instructions to warps based on a particular scheduling policies).
- A substantial number of registers. (an SM may be running a large number of active threads at a time, so it is a must to have registers in thousands).
The hardware schedules thread blocks to an SM. All threads within a particular thread block must reside on a single SM. In general, an SM can handle multiple thread blocks at the same time. An SM may contains up to 8 thread blocks in total. A thread ID is assigned to a thread by its respective SM.
Whenever an SM executes a thread block it will execute entirely on that SM. All the threads inside the thread block are executed at the same time. Hence to free a memory of a thread block inside the SM, it is critical that the entire set of threads in the block have concluded execution.
At the hardware level on the SM, each thread block is broken down into chunks of 32 consecutive threads, referred to as warps. Instructions are issued at the warp level. That is to say an instruction is issued in vector like fashion to 32 consecutive threads at a time. This execution model is referred to as Single Instruction Multiple Thread, or SIMT.
Warps
On the hardware side, a thread block is composed of warps. A warp is a set of 32 threads within a thread block such that all the threads in a warp execute the same instruction. These threads are selected serially by the SM. Each warp is executed in a SIMD fashion (i.e. all threads within a warp must execute the same instruction at any given time).
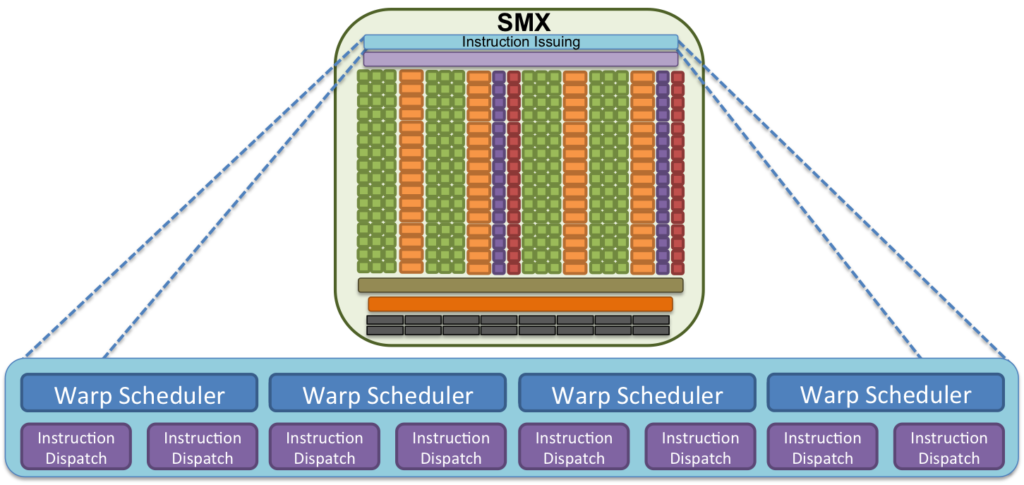
When a block is divided up into warps, each warp is assigned to a warp scheduler. Warps will stay on the assigned scheduler for the lifetime of the warp. The scheduler is able to switch between concurrent warps, originating from any block of any kernel, without overhead. When one warp stalls — that is, the next instruction can not be executed in the next cycle — the scheduler will switch to a warp that is able to execute an instruction. When an instruction has no data dependencies, that is, both of its operands are ready, the respective warp is considered to be ready for execution. The low overhead warp swapping allows for instruction latency to be effectively hidden, assuming enough warps with issuable instructions reside on the SM. If more than one warps are eligible for execution, the parent SM uses a warp scheduling policy for deciding which warp gets the next fetched instruction.

Suppose 4 clock cycles are needed to dispatch the same instruction for all threads in a warp. If there is one global memory access every 4 instructions, how many warps are needed to fully tolerate 200-cycle memory latency?
The first warp will run for 16 cycles before a memory access is required. After this time this warp needs to wait for 200 cycles. At this time the warp scheduler can switch to another warp and start executing its first 4 instructions. After another 16 cycles this process repeats until the scheduler can switch back to the original warp after 200 cycles.
So number of warps = ceil(200/16) = 13.
Example
Consider the following GPU specification. These are the maximum values
- 512 threads/block
- 1024 threads/SM
- 8 blocks/SM
Consider the following matrix multiplications thread blocks.
8 * 8
This would require 64 threads within a block. Since there are at max 8 blocks in the SM, 64*8 = 512 is the number of threads can be run. However, the SM allows upto 1024 threads. So, it will be running at half its capacity.
Another way to look at this is in terms of the number of blocks needed. To run at peak capacity, 1024 threads will be partitioned into 1024/64 = 16 blocks. However, the SM only allows upto 8 blocks. So it has to run at half its capacity.
16 * 16
This would require 256 threads within a block. Since there are at max 8 blocks in the SM, 256*8 = 2048 is the number of threads can be run. However, the SM allows upto 1024 threads. So, either 2 such SM or twice the time will be needed.
Another way to look at this is in terms of the number of blocks needed. To run at peak capacity, 1024 threads will be partitioned into 1024/256 = 4 blocks. However, the SM allows upto 8 blocks. So, it can be run for twice the time.