The below figure shows a representation of Continuous Bag-of-Word Model with only one word in the context. There are three layers in total. The units on adjacent layers are fully connected.
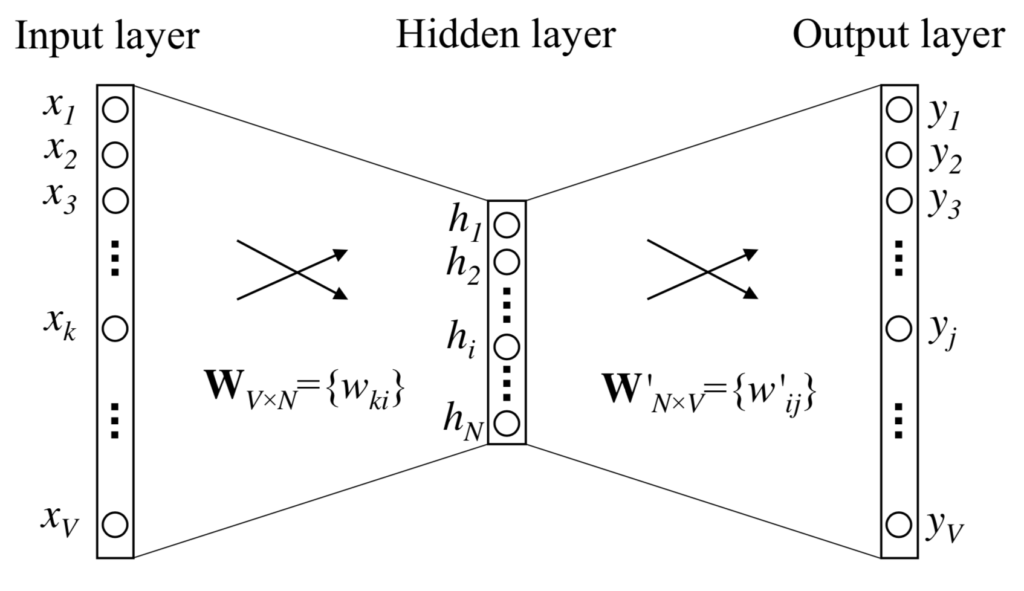
Notations
- There are
 words in the vocabulary.
words in the vocabulary. - The input layer is of size and indexed using
 .
. - The output layer is of size and indexed using
 .
. - The hidden layer is of size
 and indexed using
and indexed using  .
.  is the weight matrix connecting the input layer and the hidden layer. has dimensions
is the weight matrix connecting the input layer and the hidden layer. has dimensions  .
.- An individual element in the weight matrix is denoted by
 . Here.
. Here.  and
and  .
.  is the weight matrix connecting the hidden layer and the output layer. has dimensions
is the weight matrix connecting the hidden layer and the output layer. has dimensions  .
.- An individual element in the weight matrix is denoted by
 . Here. and
. Here. and  .
.
Input
The input is a one-hot encoded vector. This means that for a given input context word, only one out of units,  , will be
, will be  , and all other units are
, and all other units are  .
.
Consider an input word  . Given a one-word context and the above one-hot encoding,
. Given a one-word context and the above one-hot encoding,  and
and  for
for  .
.

Input-Hidden Weights
is the weight matrix connecting the input layer and the hidden layer. has dimensions .

An individual element in the weight matrix is denoted by . Here. and . The transpose of the matrix is

From the network, the hidden layer is defined as follows


which is essentially copying the -th column of  (= -th row of ) to
(= -th row of ) to  . Thus, the -th row of is the -dimension vector representation of the input word . This is denoted by
. Thus, the -th row of is the -dimension vector representation of the input word . This is denoted by 
Hidden-Output Weights
From the hidden layer to the output layer, there is a different weight matrix  , which is an matrix.
, which is an matrix.

An individual element in the weight matrix is denoted by . Here. and . The transpose of the matrix is

From the network, the output layer is defined as follows


where  is the -th row of the matrix
is the -th row of the matrix  (= -th column of the matrix ). Thus
(= -th column of the matrix ). Thus

Each word in the vocabulary now has an associated score  . Use softmax, a log-linear classification model, to obtain the posterior distribution of words, which is a multinomial distribution.
. Use softmax, a log-linear classification model, to obtain the posterior distribution of words, which is a multinomial distribution.

where  is the output of the -th unit in the output layer.
is the output of the -th unit in the output layer.

Note that  and
and  are two representations of the word
are two representations of the word  . comes from rows of , which is the input
. comes from rows of , which is the input  hidden weight matrix, and comes from columns of , which is the hidden output matrix.
hidden weight matrix, and comes from columns of , which is the hidden output matrix.
Multi-Word Context
Multi-Word context is an extension of One-Word context. The input layer now has  words instead of . The below figure shows a representation of Continuous Bag-of-Word Model with multiple words in the context.
words instead of . The below figure shows a representation of Continuous Bag-of-Word Model with multiple words in the context.
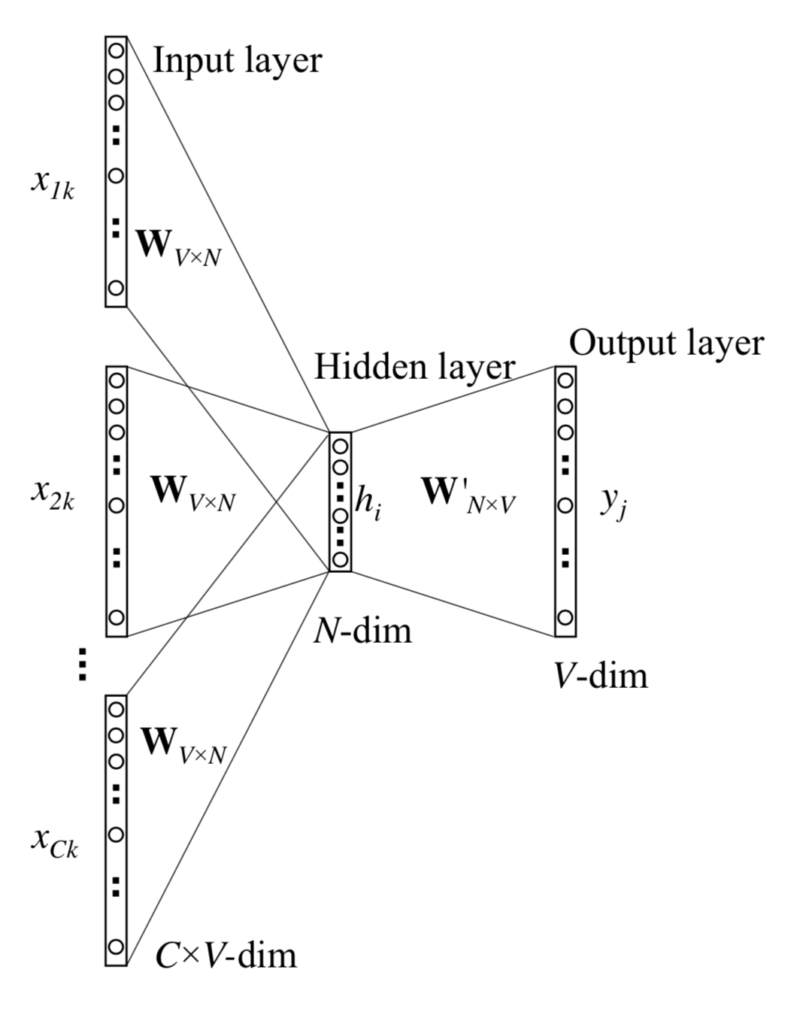
When computing the hidden layer output, instead of directly copying the input vector of the input context word, the CBOW model now takes the average of the vectors of the input context words, and use the product of the input hidden weight matrix and the average vector as the output.

where is the number of words in the context,  are the words in the context, and
are the words in the context, and  is the input vector of a word
is the input vector of a word  .
.
Skip-Gram Model
The Skip-Gram model is the opposite of the Multi-Word CBOW model. The target word is now at the input layer, and the context words are in the output layer.
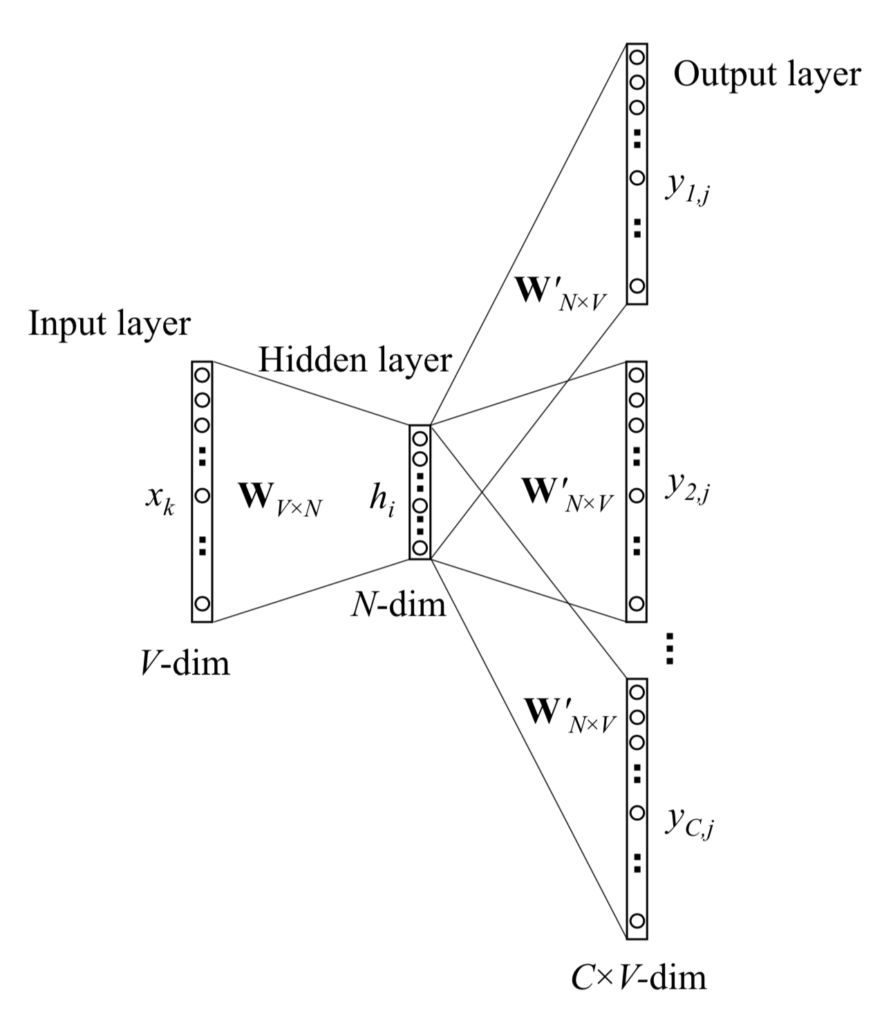
On the output layer, instead of outputing one multinomial distribution, there are multinomial distributions. Each output is computed using the same hidden output matrix

where  is the -th word on the
is the -th word on the  -th panel of the output layer;
-th panel of the output layer;  is the actual -th word in the output context words;
is the actual -th word in the output context words;  is the only input word;
is the only input word;  is the output of the -th unit on the -th panel of the output layer;
is the output of the -th unit on the -th panel of the output layer;  is the net input of the -th unit on the -th panel of the output layer. Because the output layer panels share the same weights,
is the net input of the -th unit on the -th panel of the output layer. Because the output layer panels share the same weights,

where  is the output vector of the -th word in the vocabulary,
is the output vector of the -th word in the vocabulary,  , and also is taken from a column of the hidden output weight matrix,
, and also is taken from a column of the hidden output weight matrix,  .
.