OpenCL is a low-level language for high-performance heterogeneous (supports multiple devices) data-parallel computation. It is based on C99. OpenCL gives access to all compute devices in the system – CPUs, GPUs, Accelerators. Although CUDA has better tools, language, and features it works only with NVIDIA GPUs. OpenCL supports more devices.
Platform Model
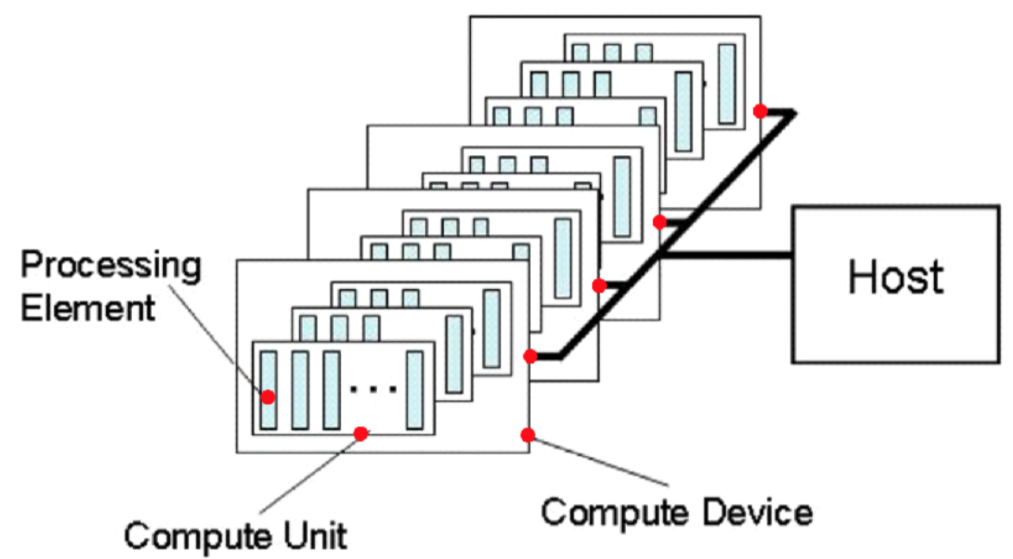
The platform model consists of a host connected to one or more OpenCL devices. An OpenCL device is divided into one or more compute units (CUs) which are further divided into one or more processing elements (PEs). Computations on a device occur within the processing elements.
An OpenCL application is implemented as both host code and device kernel code. The host code portion of an OpenCL application runs on a host processor according to the models native to the host platform. The OpenCL application host code submits the kernel code as commands from the host to OpenCL devices. An OpenCL device executes the command’s computation on the processing elements within the device. The processing elements execute code as SIMD or SPMD.
Execution Model
The OpenCL execution model is defined in terms of two distinct units of execution: kernels that execute on one or more OpenCL devices and a host program that executes on the host. With regard to OpenCL, the kernels are where the “work” associated with a computation occurs. This work occurs through work-items that execute in groups (work-groups).
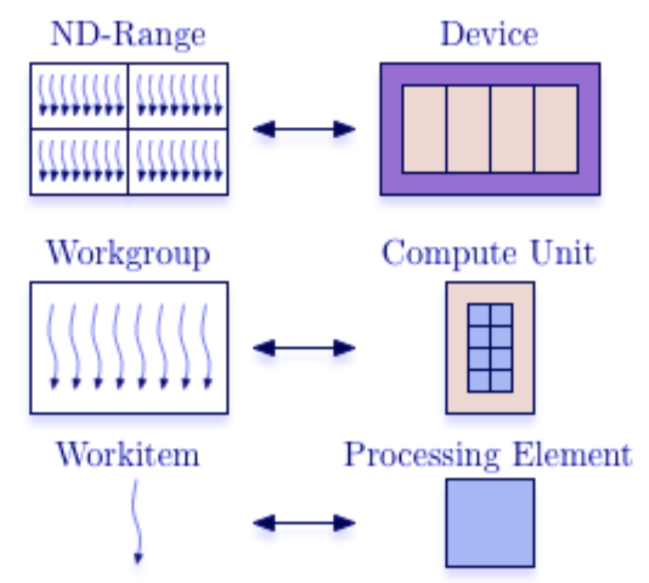
A kernel executes within a well-defined context managed by the host. The context defines the environment within which kernels execute. The host program uses the OpenCL API to create and manage the context. Functions from the OpenCL API enable the host to interact with a device through a command-queue. Each command-queue is associated with a single device.
The core of the OpenCL execution model is defined by how the kernels execute. When a kernel-enqueue command submits a kernel for execution, an index space is defined. The kernel, the argument values associated with the arguments to the kernel, and the parameters that define the index space define a kernel-instance. When a kernel-instance executes on a device, the kernel function executes for each point in the defined index space. Each of these executing kernel functions is called a work-item. The work-items associated with a given kernel-instance are managed by the device in groups called work-groups. These work-groups define a coarse grained decomposition of the Index space. Work-items have a global ID based on their coordinates within the Index space. They can also be defined in terms of their work-group and the local ID within a work-group.