Miss Penalty is defined as the time required to fetch a block into a level of the memory hierarchy from the lower level. This include the time to access the block, transmit it from one level to the other, insert it in the level that experienced the miss and then pass the block to the requester. The time to access the next level in the hierarchy is the major component of the miss penalty.
Multilevel Caches
The first-level cache is designed to be small. This ensures smaller hit time. The second-level cache is designed to be large. This would capture memory accesses that were missed in the first-level. Thus, processor doesn’t need to request the main memory thereby reducing the effective miss penalty.


There are lesser number of hits in the second-level cache than in the first-level cache. Thus, in the second-level cache the emphasis shifts to fewer misses. Second-level caches favor this by using larger blocks and higher associativity.
Priority to Read Misses over Writes
This optimization serves read requests before writes to memory have been completed.
With a write-through cache, Write Buffers might hold the updated value of a location needed on a read miss. The contents of the Write Buffer is checked on a read miss, and if there are no conflicts and the memory system is available, let the read miss continue.
For a write-back cache, suppose a read miss will replace a dirty memory block. Instead of writing the dirty block to memory, and then reading memory, the dirty block is copied to the Write Buffer, followed by a read and write operation.
Hardware Prefetching – Stream Buffer
Hardware prefetching relies on the hardware being able to analyze the data access pattern and predict the next data location that needs to be Cached. The most common case of prefetching is accessing the next block. The hardware prefetches this data either directly into the Cache or into a Stream Buffer.
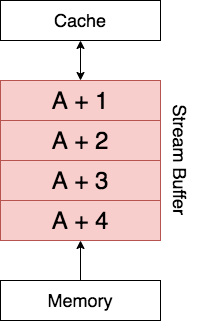
Suppose that the data at address  needs to be accessed and leads to a Cache Miss. In addition to this data being loaded into the Cache, the stream buffer prefetches successive blocks into the Stream Buffer. In the above example the Stream Buffer can hold
needs to be accessed and leads to a Cache Miss. In addition to this data being loaded into the Cache, the stream buffer prefetches successive blocks into the Stream Buffer. In the above example the Stream Buffer can hold  blocks. It would prefetch
blocks. It would prefetch  ,
,  ,
,  ,
,  and hold them in the buffer. This buffer acts like a queue. If the processor requires the data at next, the queue moves up one block and
and hold them in the buffer. This buffer acts like a queue. If the processor requires the data at next, the queue moves up one block and  gets added to the buffer. This pattern of prefetching successive blocks is called Sequential Prefetching.
gets added to the buffer. This pattern of prefetching successive blocks is called Sequential Prefetching.
Since successive blocks are available in the Stream Buffer, if processor requests for these blocks won’t lead to a Cache Miss.
Critical Word First and Early Restart
This optimization is explained in this post
Merging Write Buffer
This optimization is explained in this post