Miss Rate is defined as the fraction of memory accesses not found in a level of the memory hierarchy. The following optimizations reduce Miss Rate.
Larger Block Size
A larger block size holds more number of words in the Cache. By the principle of spatial locality, if a data address location is referenced, nearby addresses will tend to be referenced soon. Having a larger block size ensures that when a word is referenced and brought into the Cache, sufficient nearby words are also available for future access. Thus, increasing the block size reduces the Miss Rate.
However, larger blocks increase miss penalty. This is because loading a larger block into the Cache will take longer. The increase in miss penalty may outweigh the decrease in Miss Rate.
Larger Cache Size
A larger overall Cache will have more number of blocks. This results in an increase in Cache capacity. Thus, the chances of the data being present in the Cache increases. This reduces the Miss Rate.
However, increasing the number of blocks will require more number of tag comparisions to search for the relevant block. So, a larger Cache may increase the Hit Time.
Higher Associativity
Increasing the associativity increases the number of slots available for a frame in a set. There will be less conflict between data addresses that map to the same set. Thus, increasing the associativity increases the chances of data being present in the Cache and reduces Miss Rate. A directly mapped cache of size  has about the same miss rate as a two-way set associative cache of size
has about the same miss rate as a two-way set associative cache of size  .
.
However, increasing the associativity of blocks will require more number of tag comparisions within a set. So, increasing associativity may increase the Hit Time.
Hardware Prefetching – Stream Buffer
Hardware prefetching relies on the hardware being able to analyze the data access pattern and predict the next data location that needs to be Cached. The most common case of prefetching is accessing the next block. The hardware prefetches this data either directly into the Cache or into a Stream Buffer.
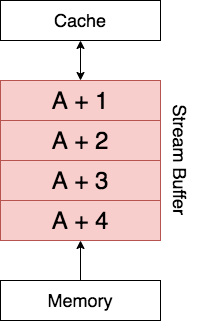
Suppose that the data at address  needs to be accessed and leads to a Cache Miss. In addition to this data being loaded into the Cache, the stream buffer prefetches successive blocks into the Stream Buffer. In the above example the Stream Buffer can hold
needs to be accessed and leads to a Cache Miss. In addition to this data being loaded into the Cache, the stream buffer prefetches successive blocks into the Stream Buffer. In the above example the Stream Buffer can hold  blocks. It would prefetch
blocks. It would prefetch  ,
,  ,
,  ,
,  and hold them in the buffer. This buffer acts like a queue. If the processor requires the data at next, the queue moves up one block and
and hold them in the buffer. This buffer acts like a queue. If the processor requires the data at next, the queue moves up one block and  gets added to the buffer. This pattern of prefetching successive blocks is called Sequential Prefetching.
gets added to the buffer. This pattern of prefetching successive blocks is called Sequential Prefetching.
Since successive blocks are available in the Stream Buffer, if processor requests for these blocks won’t lead to a Cache Miss.
Compiler Optimization – Loop Interchange
Consider the following code snippet
for i = 0 to N-1
for j = 0 to N-1
A[j][i] = i*j;
The term ![A[j][i]](http://thebeardsage.com/wp-content/ql-cache/quicklatex.com-d60d615c8463343949d4334a56eec1f3_l3.png "Rendered by QuickLaTeX.com") will first load the memory content at
will first load the memory content at ![A[j]](http://thebeardsage.com/wp-content/ql-cache/quicklatex.com-cd79877a7a2bc8eedba50b911d1d2caf_l3.png "Rendered by QuickLaTeX.com") followed by indexing using
followed by indexing using  . However, the innermost loop increments
. However, the innermost loop increments  . So in the first iteration of the loop, the memory content at
. So in the first iteration of the loop, the memory content at ![A[0]](http://thebeardsage.com/wp-content/ql-cache/quicklatex.com-bd0469a244b0d589019f298b25af0a9a_l3.png "Rendered by QuickLaTeX.com") is loaded. This is followed by indexing
is loaded. This is followed by indexing  within . In the second iteration, the memory content at
within . In the second iteration, the memory content at ![A[1]](http://thebeardsage.com/wp-content/ql-cache/quicklatex.com-02744b3c20e58f0e338eea1a7fa149c1_l3.png "Rendered by QuickLaTeX.com") is loaded, followed by indexing within .
is loaded, followed by indexing within .
This is very inefficient. Loading the entire array into the cache doesn’t benefit the processor if only one element within this array is accessed. In fact, if is large, the above execution will cause a Cache Miss on every iteration.

The above code snippet can exchange the loops as shown below
for j = 0 to N-1
for i = 0 to N-1
A[j][i] = i*j;
Now, once the array at is loaded into the Cache, all elements within this array are indexed using . All elements except the first one result in a Cache Hit because the memory contents of the array are already present in the Cache.

A compiler can optimize these kinds of code by interchanging the order of loops. This process reduces the Miss Rate by improving spatial locality.
Compiler Optimization – Blocking
Another compiler optimization involves processing the data in arrays like above as blocks. If multiple operations need to be performed on each data element in an array, it is more efficient to finish all these operations as soon as they are loaded in the Cache. A subset of the data array (called a block) is loaded into the Cache during initial access. This data in the Cache is reused until no more operations need to be performed. After this, another block is loaded and this process repeats.

In the above example blocks of  are processed. This process reduces the Miss Rate by improving temporal locality.
are processed. This process reduces the Miss Rate by improving temporal locality.
Compiler Optimization – Prefetching
This optimization is targeted for loops that run over a large number of iterations. Consider the following loop
for i = 0 to N-1
A[i] = 2 * A[i]
Each element access will cause a Compulsory miss. This is very inefficient especially when is large. At each iteration, the th element of the array is accessed. The elements that are needed in a future iteration can be prefetched by the compiler to improve efficiency.
for i = 0 to N-1
prefetch(A[i + k])
A[i] = 2 * A[i]
Now  future elements of the array are prefetched. The value of will depend on the Cache Miss Penalty and the time it takes to run one iteration of the loop.
future elements of the array are prefetched. The value of will depend on the Cache Miss Penalty and the time it takes to run one iteration of the loop.